1. Getting Started
CHREST is a cognitive architecture covering processes of visual attention, memory, categorisation and simple problem solving. The CHREST software provides a graphical interface for some common types of models, and can also be used as a library to develop more sophisticated experiments or CHREST-based agents in a programming language of your choice.
This document introduces the CHREST software, its capabilities and typical uses.
1.1. Download
Source code and a precompiled version are available for the latest version.
After downloading "chrest-NNN.zip" (where NNN refers to the latest version number), unpack the file to obtain the "chrest" folder.
The folder contains some documentation, including a copy of this user guide and
a manual, the chrest.jar software, and a folder of examples, including
models written in different programming languages and some sample datasets.
Alternatively, use jRuby with:
-
jchrest gem - including the jCHREST implementation.
-
jchrest-chess gem - extensions to jCHREST for the classification and interpretation of chess positions.
Install these from packages.
1.2. Runtime Requirements
CHREST requires version 11 or later of the Java Runtime Environment to be installed.
-
In most cases, CHREST can be run by double-clicking on the file
chrest.jar, which will launch the graphical shell described in the next section. -
In some cases you will need to use
start-chrest.bat(on Windows) orstart-chrest.sh(on Linux or Apple) to ensure the Java run-time is correctly called. -
If you have special memory requirements, you will also need to edit the number after the flag
-Mmxin thestart-chrestscript. Alternatively, use the standard ways to manage the Java Virtual Machine appropriate to your platform.
1.3. Technical Details
The CHREST software has been written by Peter Lane, and is released under the MIT License. The software largely replicates and extends the earlier Lisp version of CHREST, implemented by Fernand Gobet.
The latest version includes contributions by Marvin Schiller and Martyn Lloyd-Kelly.
This version of CHREST includes the XChart software, licensed under an Apache license, and available from: https://knowm.org/open-source/XChart/
See the docs folder for copies of licenses.
2. Graphical Environment
The graphical environment supports the development of simple models, and provides facilities to drive experiments and view information on the resulting model and performance. The main frame the user sees provides a menu for the "Data", from which a dataset may be opened. When a dataset is opened, the main part of the frame will contain a set of controls appropriate to that dataset; examples follow below. The other menu is for the "Model", providing access to a view of the model and a dialog to change its properties.
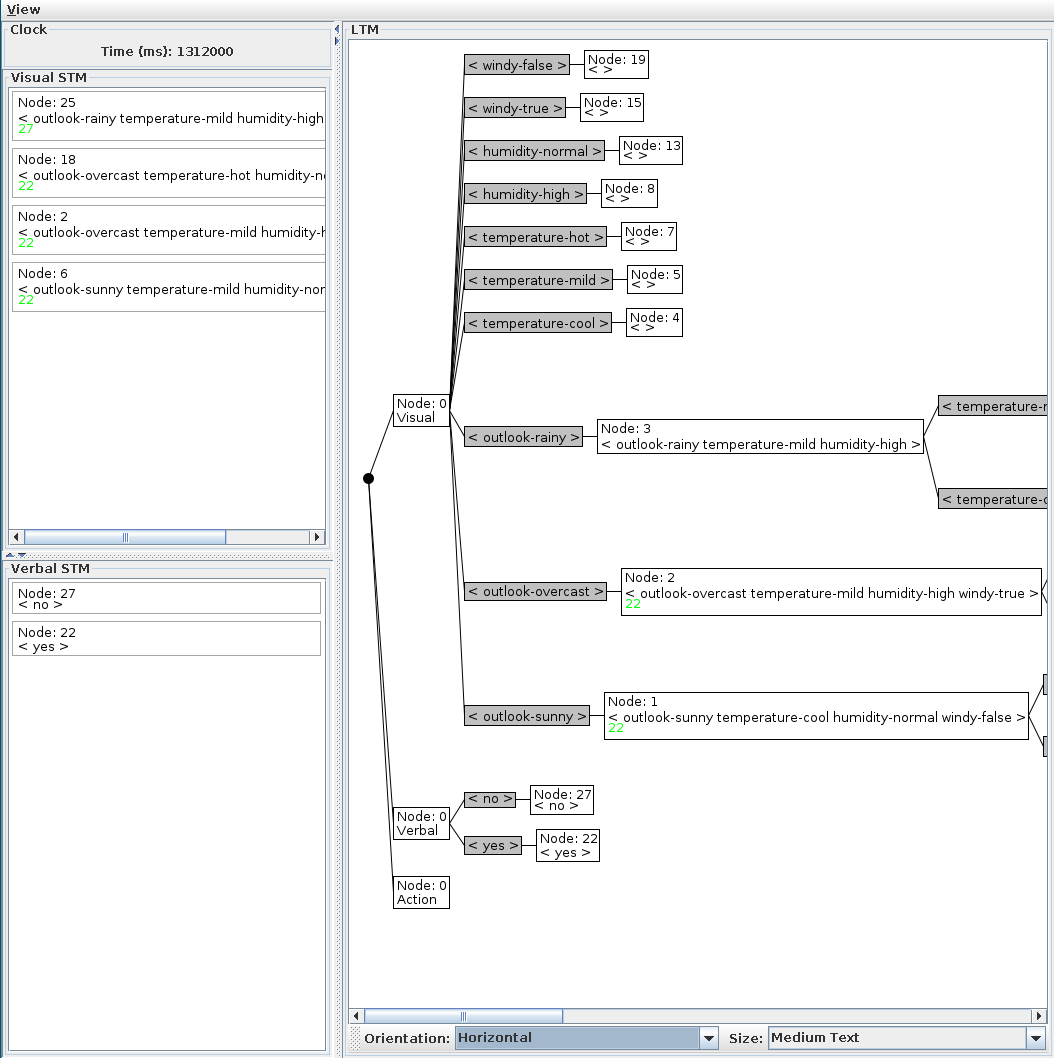
Figure 1 shows the main components of the model’s view. The current time of the model is shown in the top left corner; two scrollable boxes for the short-term memories show the contents of the nodes referred to; and the right-hand side shows the long-term memory network. Various parts of the display may be modified: the long-term memory’s orientation and size, and resizable bars let you alter the amount of each window that is occupied. The "View" menu provides an option to save the long-term memory image to a file. You may open several view windows onto the same model, and they will all update as the model changes. This enables you to look at different parts of the long-term memory or details of the short-term memory separately.
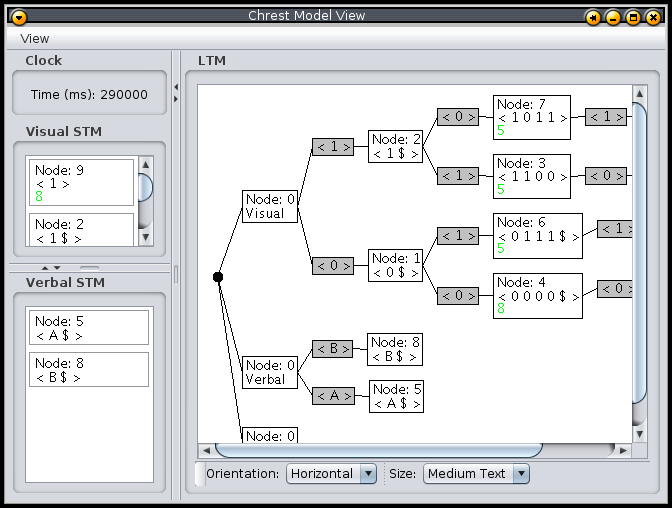
Figure 1: View of model. The LTM shows test links (in grey) and node images. Each node has a unique number, and lateral links are shown by the coloured numbers.
The Model/Properties menu option opens a dialog box, shown in Figure 2, to view or change the parameters of the current CHREST model. Experimental data and definitions are provided through text files. The main types are described below.
Figure 2: Dialog box to view or change parameters of a CHREST model.
3. Supported Domains
The graphical environment provides direct support for a number of typical domains and demonstrations.
3.1. Learn and recognise
The basic operations within CHREST are to learn about a new pattern and to
retrieve a familiar pattern when given a stimulus. The learn-and-recognise
display allows the user to explore the basic learning mechanisms of the model.
The display is shown in Figure 3. The list of patterns
is read from a data file. The user highlights a pattern, and then uses one of
the buttons on the right either to "Learn" that pattern, or to "Recognise" that
pattern. On clicking "Recognise" the display will show the image of the node
retrieved when the highlighted pattern is sorted through the network. In this
case, the pattern <a b> has been retrieved. To speed up learning,
the user can use the "Learn all" button to learn each pattern once.
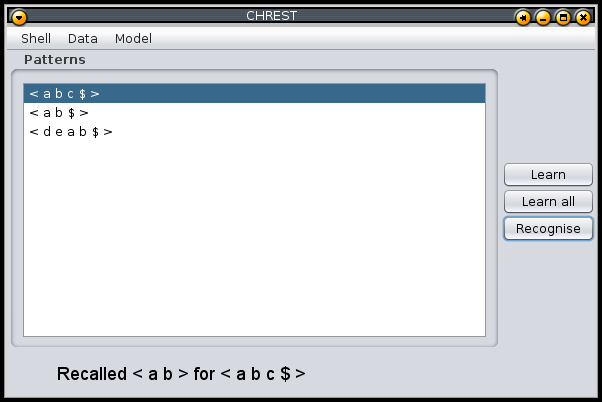
Figure 3: Learn and recognise display.
No timing parameters are used in this system, and so it is ideal for observing the basic learning mechanisms within CHREST by keeping a view of the model open to one side. An example data file is:
recognise-and-learn a b c a b d e a b
The file starts with the keyword "recognise-and-learn". Each pattern is on its own line. The atoms are separated by spaces. The end marker is automatically added to each pattern as it is defined, and so should not be part of the data file.
3.2. Paired associate learning
This form of learning is about learning that one pattern is typically associated with a second pattern: for example, seeing the word "dog" and associating it with the word "cat". The verbal-learning paradigm was important in psychological research when EPAM was being developed, and the core learning mechanisms of EPAM and subsequently CHREST are based on the empirical support from that time. The experimental format supported in the interface is the construction of a "subject protocol", which is a trial-by-trial list of all the responses made by the human participant in the experiment. For this kind of task, the CHREST model forms sequence links between nodes of the same type in its long-term memory; these links are shown in the model view as a blue number inside the node, the number indicating the linked node.
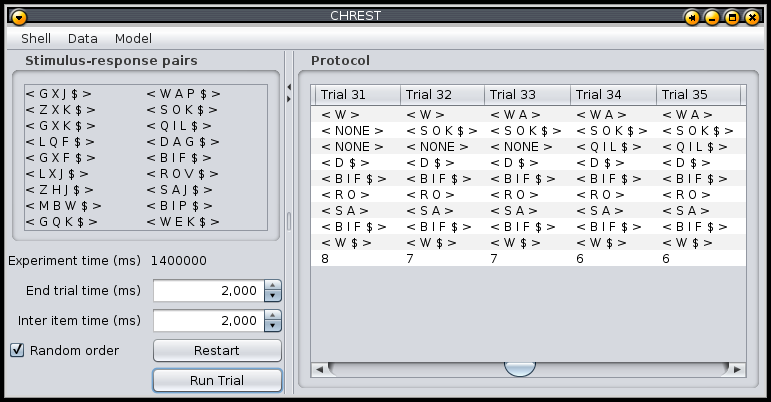
Figure 4: Example of subject protocol for CHREST model of stimulus-response experiment.
Figure 4 shows a typical view of the controls for this type of experiment. The controls on the left display the list of stimulus-response pairs forming one set of data. The times for which each item in the list is presented, and also the time before the next trial is made, may be altered. The order of presentation may be as written or random, if the checkbox is ticked. The "Run Trial" button will respect the given timings and present each pattern in the list exactly once to the CHREST model. The model’s response to each stimulus is provided in a new column in the protocol display to the right of the display. A count of the number of errors, responses that are not identical to the target response, is provided below each column.
There are two forms of the verbal-learning experiment. The first is the paired-associate experiment, where each pair is independent of the other pairs in the list. The second is the serial-anticipation task, where the idea is to learn the sequence of patterns. Both tasks can be controlled through the above dialog (although for the second the "random order" option should not be used). They have different definition files. The serial-anticipation experiment is simply a list of patterns, with each item in each pattern separated by a space. The paired-associate experiment uses a list of pairs of patterns. Each pair is provided on its own line in the definition file, and the individual patterns of each pair are separated by a colon.
serial-anticipation paired-associate
D A G G X J : W A P
B I F Z X K : S O K
G I H G X K : Q I L
J A L L Q F : D A G
M I Q G X F : B I F
P E L L X J : R O V
S U J Z H J : S A J
M B W : B I P
G Q K : W E K
3.3. Categorisation
Categorisation is the process of assign labels to patterns. We typically handle categorisation in CHREST by providing the patterns to be named as visual patterns, and the labels as verbal patterns. Naming links are formed between the two nodes as they co-occur during training; naming links are shown by displaying the number of the linked node in green.
Figure 5 depicts the categorisation experiment display. This is very similar to that used in the verbal-learning above. The second of the two patterns is a verbal pattern, not a visual pattern. Also, using the tick boxes beside each pattern, the user can select which ones will form part of the training data, and which only used for test. The protocol is based on the response of the model to each visual pattern, after each training cycle.
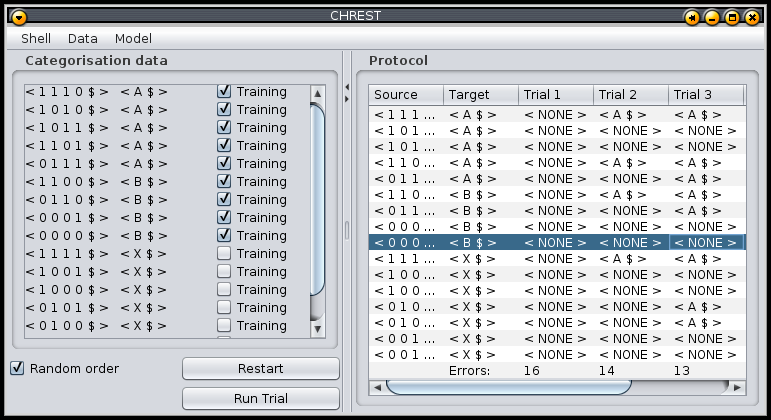
Figure 5: Categorisation experiment display
The data definition file for a categorisation experiment is very similar to that for the paired-associate task, with the pattern to be named and its name presented on the same line, separated by a colon:
categorisation 1 1 1 0 : A 1 0 1 0 : A 1 0 1 1 : A 1 1 0 1 : A 0 1 1 1 : A 1 1 0 0 : B 0 1 1 0 : B 0 0 0 1 : B 0 0 0 0 : B 1 1 1 1 : X 1 0 0 1 : X 1 0 0 0 : X 0 1 0 1 : X 0 1 0 0 : X 0 0 1 1 : X 0 0 1 0 : X
3.4. Visual attention and recall
CHREST has been used to model the visual attention processes and memory of experts in domains such as chess. The CHREST shell supports experiments in chess and related domains.
Figure 6 shows the controls for training a model on a set of scenes. The drop-down box at the top allows selection of the domain: specific domains tailor internal processes within CHREST and add heuristics, such as following lines of attack/defence. The aim of training is to create a CHREST model of a given size. The choice of maximum number of training cycles is to place an upper limit on training times. When the parameters are chosen, the "train" button should be clicked, and the model will be created. The graph and progress bar will show progress towards the target number of chunks; the process may be stopped by clicking the "stop" button.
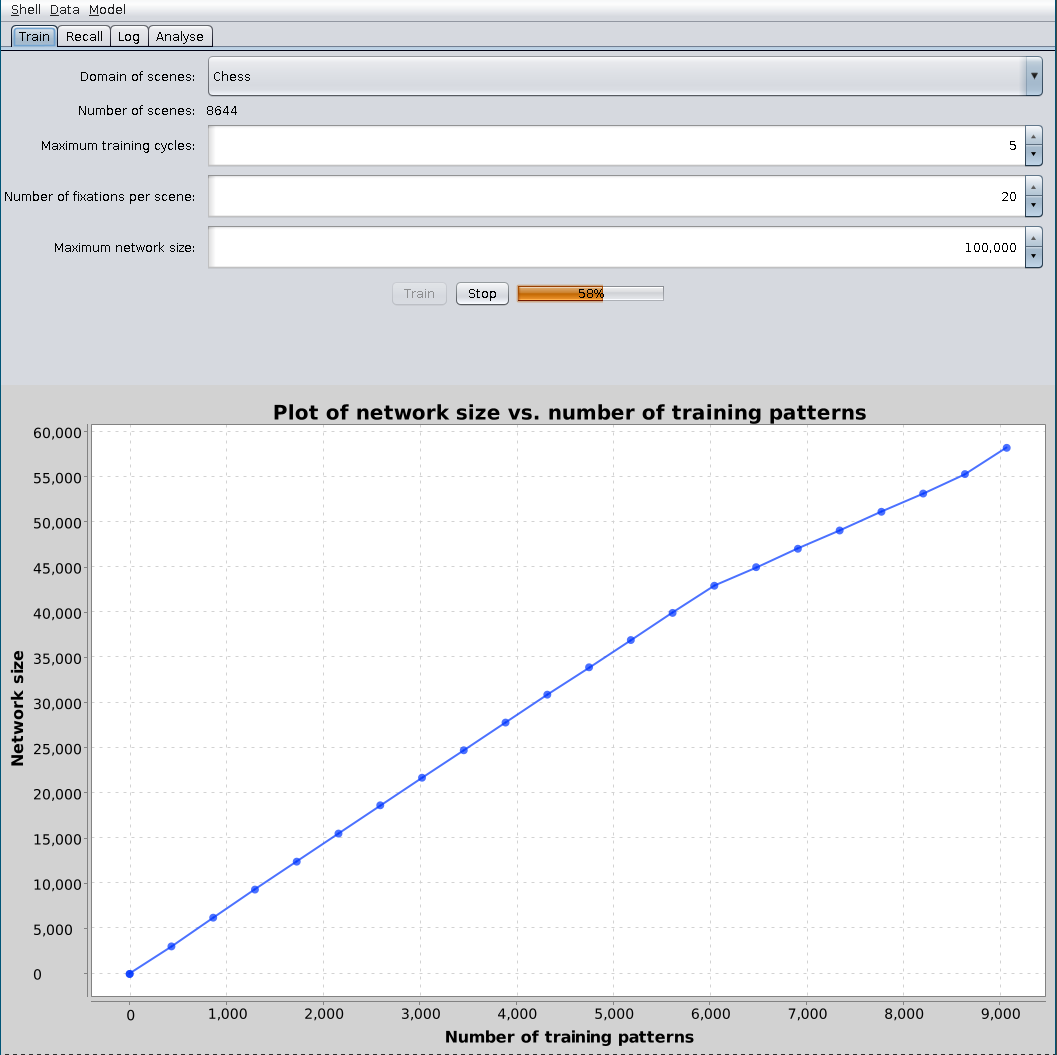
Figure 6: Training a model from a set of scenes.
Once trained, the model’s recall performance can be tested. It is possible to use a separate set of files for recall by opening a new data file with the test files; the model will not be changed. Figure 7 shows the screen on the "recall" tab. At the top, a drop-down list can be used to select the target scene. The button on the right will cause the model to scan the target scene, and the recalled scene will be shown in the lower image. Some statistics on performance are also shown.
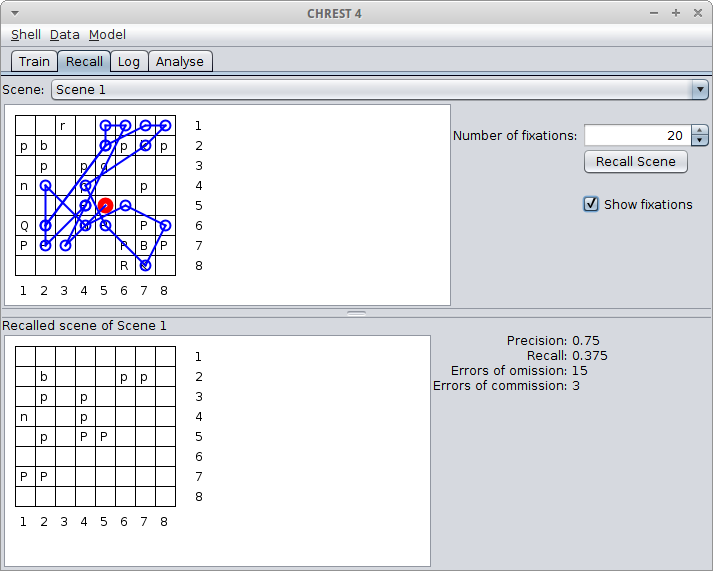
Figure 7: Recall of a chess board.
The data definition file for visual stimuli starts with the label "visual-search", then the height and width of the patterns separated by a space. A blank line precedes the definition of the stimuli. A full stop indicates an empty space. The following example defines two chess positions:
visual-search 8 8 ..r..... pb...pkp .p.pq... n..p..p. ...P.... Q..NP.P. PP...PBP .....RK. r..q.rk. .p...p.. p.n.p.p. ....Pnbp P....B.. ..NB.... .PP.Q.PP R....R.K
4. Scripting
Although the graphical environment is useful for learning about CHREST, serious modelling typically requires more control over the models and experimental setup. As CHREST runs on the Java virtual machine, any language which the Java virtual machine supports can be used to develop CHREST-based models. The folder of examples includes scripts for a variety of languages including Java, Lisp, Python and Ruby.
The javadoc documentation is provided for all classes within the CHREST library:
-
open the file "documentation/javadoc/index.html" in your browser.
For most small projects, it is easy to create scripts using a reasonable editor and running from the command line. However, it is also possible to use a development environment such as NetBeans or, for Lisp users, an appropriate editor such as Emacs+SLIME. In most cases, all you need to do is add the CHREST jar file to your CLASSPATH or IDE project file and your JVM-based scripting language will be able to use it.
The next subsections give a brief introduction to writing CHREST models in different languages, and then follow with descriptions of more detailed models. All the example scripts and models are included with the CHREST files.
4.1. Language Examples
4.1.1. Java
As CHREST is written in the Java language, the chrest.jar file can be used as a library
in a Java program to build CHREST models.
Recent versions of Java can run Java programs without pre-compiling them, and this is ideal
for smaller models in single-files. For example, the first demonstration program should be
saved in a file called "Demo1.java", and called with chrest.jar on the CLASSPATH, e.g.:
$ java -cp chrest.jar Demo1.java
The following scripts have been tested using JDK 13.0.1.
4.1.2. Lisp
Lisp is supported on the JVM through ABCL. A separate file, including the Lisp environment and supporting files, is available on the CHREST website.
4.1.3. Python
To run CHREST from Python, you can use jython, an implementation of Python 2.7 for the JVM, available from https://jython.org/downloads.html
Either install jython using the installer, and run
$ jython demo-1.py
Or download the standalone jython jar file, and run
$ java -jar jython-standalone-2.7.0.jar demo-1.py
4.1.4. Ruby
All of the classes and methods available in CHREST are similarly available through JRuby. Some convenience functions are provided in a self-contained CHREST library. Also, JRuby provides some other conveniences, such as that method names can be called using snake rather than camel case, or that get/set accessors in Java are mapped to simple variable accesses, as used in Ruby.
CHREST for jRuby is available as a gem: https://rubygems.org/gems/jchrest/
When using CHREST from Ruby, we must first include the "jchrest" library:
require "jchrest"4.2. Basic Learning Demonstration
The following demonstration program illustrates the basic operations of creating a model, making some patterns to learn, and then training the model. Finally, the model is tested and the state of the model is displayed visually.
This example is presented for all four language examples, to give a flavour of how CHREST can be used in each.
4.2.1. Java
import jchrest.architecture.Chrest;
import jchrest.gui.ChrestView;
import jchrest.lib.ListPattern;
import jchrest.lib.Pattern;
/*
* Demonstration 1 : Java program
*
* In this example, we create some instances of patterns,
* train a CHREST model with them, and then print out and
* display what CHREST has learnt.
*/
public class Demo1 {
public static void main (String[] args) {
// create an instance of the CHREST model
var model = new Chrest ();
// create three pattern instances
var pattern1 = Pattern.makeVisualList(new int[]{1, 2, 3});
var pattern2 = Pattern.makeVisualList(new int[]{1, 3, 2});
var pattern3 = Pattern.makeVisualList(new int[]{2, 1, 3});
// and store them in an array
ListPattern[] patterns = {pattern1, pattern2, pattern3};
// Train the model a few times on the patterns
for (int i = 0; i < 4; i += 1) {
for (ListPattern pattern : patterns) {
model.recogniseAndLearn (pattern);
}
}
// Display the results
System.out.println ("Current model time: " + model.getClock ());
for (ListPattern pattern : patterns) {
System.out.print ("For pattern: " + pattern + " model retrieves ");
System.out.println ("" + model.recallPattern (pattern));
}
// And display the model in a graphical view
new ChrestView (model);
}
}4.2.2. Lisp
The Lisp version relies on a supporting package, in "chrest.lisp", to ease the transition from Lisp to the JVM environment.
(load "chrest.lisp")
(use-package :chrest)
(let* ((model (make-chrest))
(pattern-1 (make-list-pattern '(1 2 3)))
(pattern-2 (make-list-pattern '(1 3 2)))
(pattern-3 (make-list-pattern '(2 1 3)))
(patterns (list pattern-1 pattern-2 pattern-3)))
;; train the model a few times on the patterns
(dotimes (_ 4)
(dolist (pattern patterns)
(recognise-and-learn model pattern)))
;; display the results
(format t "Current model time: ~d~&" (get-clock model))
(dolist (pattern patterns)
(format t "For pattern ~s model retrieves ~s~&"
(to-string pattern)
(to-string (recall-pattern model pattern))))
;; display the model in a graphical window
(display-model model))4.2.3. Python
The Python version is a straightforward conversion of the Java code.
import sys
sys.path.append("chrest.jar") # assumes chrest.jar is in the same directory as the script
from jchrest.architecture import Chrest
from jchrest.gui import ChrestView
from jchrest.lib import Pattern
import java.lang.System
import java.io.PrintStream
# Create an instance of the Chrest model
model = Chrest()
# Create three pattern instances
pattern1 = Pattern.makeVisualList([1, 2, 3])
pattern2 = Pattern.makeVisualList([1, 3, 2])
pattern3 = Pattern.makeVisualList([2, 1, 3])
# store them in an array
patterns = [pattern1, pattern2, pattern3]
# Train the model a few times on the patterns
for _ in range(4):
for pat in patterns:
model.recogniseAndLearn(pat)
# Display the results
print("Current model time: " + str(model.getClock()))
for pat in patterns:
print("For pattern: " + pat.toString() +
" model retrieves " + model.recallPattern(pat).toString())
# And display the Model in a graphical view
ChrestView(model)4.2.4. Ruby
The following script produces the same effect, but using Ruby.
require "jchrest"
# Create an instance of the Chrest model
model = Chrest.new()
# Create three pattern instances
pattern1 = JChrest.make_number_pattern([1, 2, 3])  pattern2 = JChrest.make_number_pattern([1, 3, 2])
pattern3 = JChrest.make_number_pattern([2, 1, 3])
# store them in an array
patterns = [pattern1, pattern2, pattern3]
# Train the model a few times on the patterns
4.times do
for pat in patterns
model.recognise_and_learn(pat)
pattern2 = JChrest.make_number_pattern([1, 3, 2])
pattern3 = JChrest.make_number_pattern([2, 1, 3])
# store them in an array
patterns = [pattern1, pattern2, pattern3]
# Train the model a few times on the patterns
4.times do
for pat in patterns
model.recognise_and_learn(pat)  end
end
# Display the results
puts "Current model time: #{model.clock}"
end
end
# Display the results
puts "Current model time: #{model.clock}"  for pat in patterns
print "For pattern: #{pat} model retrieves "
puts "#{model.recall_pattern(pat)}"
end
# And display the Model in a graphical view
ChrestView.new(model)
for pat in patterns
print "For pattern: #{pat} model retrieves "
puts "#{model.recall_pattern(pat)}"
end
# And display the Model in a graphical view
ChrestView.new(model)JChrest provides some convenient functions for creating list-patterns.
You can still use the Java versions, if you prefer. |
|
The Java recogniseAndLearn method name can be written as a Ruby-like recognise_and_learn. |
|
Java’s get/set methods can be called using Ruby attributes, e.g. clock in place of getClock(). |
4.3. Example Model: Implicit Learning
As an example model, we will look at implementing an implicit learning task, using a Reber Grammar. The model learns a number of strings, representing the valid strings for the given grammar. When tested, the model is asked to recall examples of valid and invalid strings, and determine whether the string is valid. Validity is determined by observing which chunks are retrieved when examining the string, and using a simple heuristic to decide if the retrieved chunks are "familiar enough".
Notice that a specialised training and retrieval process is required, to scan the input string, treating it one chunk at a time. This has to be coded to create the model.
More details and references can be found in the following paper:
-
P.C.R. Lane and F. Gobet, "CHREST models of implicit learning and board game interpretation", in J.Bach, B.Goertzel and M.Ikle (Eds.), Proceedings of the Fifth Conference on Artificial General Intelligence, LNAI 7716, pp. 148-157, 2012. pdf
Two example implementations of this model are given, one in Java and the other in Ruby. Both examples are included with CHREST, and generate results like the following:
*** Results ***
Valid Invalid (Actual)
3302 1098 | Valid (True)
580 3820 | Invalid
Human ACT-R CHREST
-----------------------------------------------------
Hits: 33/44 34/44 33.02 / 44.00
Correct rejections: 36/44 39/44 38.20 / 44.00
Misses: 11/44 10/44 10.98 / 44.00
False alarms: 8/44 5/44 5.80 / 44.00
(Human/ACT-R from Kennedy & Patterson (2012).
CHREST results averaged over 100 runs.)
4.3.1. Java
The following program should be placed in a file called
"ImplicitLearningModel.java", and called with chrest.jar on the CLASSPATH,
e.g.:
$ java -cp chrest.jar ImplicitLearningModel.java
We begin by including the parts of the CHREST and Java libraries required. A main
method starts the program, by creating an instance of the class and running the
experiment:
import jchrest.architecture.*;
import jchrest.lib.*;
import java.util.*;
public class ImplicitLearningModel {
public static void main (String[] args) {
var model = new ImplicitLearningModel ();
model.runCompleteExperiment ();
}
// ** Remaining code is also placed within this class
}The top-level method merely runs the experiment, and collects results which are then printed out to the screen:
void runCompleteExperiment () {
int numberRuns = 100;
int truePos = 0;
int falseNeg = 0;
int trueNeg = 0;
int falsePos = 0;
for (int i = 0; i < numberRuns; i += 1) {
int[] result = runExperiment ();
truePos += result[0];
falseNeg += result[1];
trueNeg += result[2];
falsePos += result[3];
}
System.out.println(
"\n" +
"*** Results ***\n" +
"\n" +
"Valid Invalid (Actual)\n" +
String.format("%5d %5d | Valid (True)\n", truePos, falseNeg) +
String.format("%5d %5d | Invalid\n", falsePos, trueNeg) +
"\n" +
" Human ACT-R CHREST\n" +
"-----------------------------------------------------\n" +
" Hits: 33/44 34/44 " + formatResult(truePos, falseNeg, numberRuns) + "\n" +
"Correct rejections: 36/44 39/44 " + formatResult(trueNeg, falsePos, numberRuns) + "\n" +
" Misses: 11/44 10/44 " + formatResult(falseNeg, truePos, numberRuns) + "\n" +
" False alarms: 8/44 5/44 " + formatResult(falsePos, trueNeg, numberRuns) + "\n" +
"\n" +
"(Human/ACT-R from Kennedy & Patterson (2012). \n" +
" CHREST results averaged over 100 runs.)\n"
);
}
String formatResult (int a, int b, int n) {
return String.format ("%5.2f / %5.2f", (float)a / n, (float)(a+b) / n);
}| This calls the experiment itself, and collects the four returned values. | |
| Utility method used to format the results for the output table. |
The experiment code creates the train/test datasets, and produces four values:
-
the number of valid strings it classified as valid (true positives)
-
the number of valid strings it classified as invalid (false negatives)
-
the number of invalid strings it classified as invalid (true negatives)
-
the number of invalid strings it classified as valid (false positives)
int[] runExperiment () {
var dataset = createData ();
var trainingSet = dataset.subList (0, 18);
var testSet = dataset.subList(21, dataset.size ());
var model = trainModel (trainingSet);
var valid = testModel (model, testSet, true);
var rnd = testModel (model, rndTestset (), false);  return new int[]{valid[0], valid[1], rnd[0], rnd[1]};
}
return new int[]{valid[0], valid[1], rnd[0], rnd[1]};
}| Creates a new dataset from the set of valid strings, and divides it into a training and test set. | |
| Creates and trains a model on the training set. | |
| Tests the model on the valid strings, counting how many it gets right and wrong. | |
| Tests the model on the invalid strings, counting how many it gets right and wrong. |
A CHREST model is created and built from a set of patterns. The model of implicit learning requires some additional processing beyond the core methods provided by CHREST. This is because we are simulating scanning along a sequence of items, and attempting to learn and recall them as chunks.
The training process works as follows for each pattern in turn:
-
Using
recogniseAndLearnto look up the pattern and then extend CHREST’s net with any new information. -
Using
recognise, locate the node that currently represents the given pattern, and remove from the pattern the part that is familiar to CHREST: the node’s contents, or set of tests required to reach it. -
This process is then repeated in a loop from step (1) until the retrieved pattern is identical to the remaining given pattern, or there is nothing left to learn.
Chrest trainModel (List<ListPattern> patterns) {
var model = new Chrest ();
for (ListPattern pattern : patterns) {
model.recogniseAndLearn (pattern);
var node = model.recognise (pattern);
var newPattern = pattern.remove (node.getContents ());
while (!newPattern.equals (pattern)) {
pattern = newPattern;
model.recogniseAndLearn (pattern);
node = model.recognise (pattern);
newPattern = pattern.remove (node.getContents ());
}
}
return model;
}The testing process is relatively straight-forward, except for some book keeping. Given a list of patterns, which may be valid or invalid, the model will try to recognise each one by retrieving its chunks. The retrieved chunks are then rejected if they are not substantial enough to indicate the pattern is familiar.
int[] testModel (Chrest model, List<ListPattern> patterns, boolean isValid) {
int trues = 0;
int falses = 0;
for (int i = 0; i < 2; i += 1) { // the tests are run twice
for (ListPattern pattern : patterns) {
var chunks = retrieveChunks (model, pattern);
if (rejectChunks (chunks)) {
if (isValid) { falses += 1; } else { trues += 1; }
} else {
if (isValid) { trues += 1; } else { falses += 1; }
}
}
}
return new int[]{trues, falses};
}Retrieved chunks are rejected if they meet either of two conditions: are there too many small chunks, indicating a lack of knowledge, or are there too many chunks, in which case they cannot all be held in the articulatory loop. If either of the two conditions is not met, then the pattern is classified as invalid.
boolean rejectChunks (List<ListPattern> chunks) {
// 1. number of small chunks is too large
int numSmall = 0;
for (ListPattern chunk : chunks) {
if (chunk.size () <= 1) numSmall += 1;
}
if (numSmall > 2) return true;
// 2. number of chunks is too large
if (chunks.size () > 5) return true;
// passed tests, so do not reject
return false;
}Chunks are retrieved for a given pattern in a similar manner to how they are learnt, except no learning occurs. Each pattern is scanned from start to finish, and any familiar chunks are recorded before the remaining pattern is similarly checked.
List<ListPattern> retrieveChunks (Chrest model, ListPattern pattern) {
var chunks = new ArrayList<ListPattern> ();
var node = model.recognise (pattern);
chunks.add (node.getContents ());
var newPattern = pattern.remove (node.getContents ());
while (!newPattern.equals (pattern)) {
pattern = newPattern;
node = model.recognise (pattern);
chunks.add (node.getContents ());
newPattern = pattern.remove (node.getContents ());
}
return chunks;
}We now have some functions to create the strings used in the train and test sets.
The first two methods are used to create some random strings. Notice the use of
Pattern.makeVerbalList to create a verbal list pattern, as required within CHREST.
List<ListPattern> rndTestset () {
var result = new ArrayList<ListPattern> ();
for (int i = 0; i < 7; i += 1) {
for (int size : new int[]{6,7,8}) {
result.add (Pattern.makeVerbalList (randomString(size).split("")));
}
}
result.add (Pattern.makeVerbalList (randomString(7).split("")));
return result;
}
String randomString (int n) {
var r = new Random ();
String[] letters = {"T", "X", "P", "V"};
String result;
do { // creates a random string that is _not_ in validStrings
var word = "";
while (word.length () < n-1) {
word += letters[r.nextInt(letters.length)];
}
result = word + "S"; // end with 'S'
} while (Arrays.stream(validStrings).anyMatch(result::equals));
return result;
}Finally, the valid strings are created into a list of ListPattern instances,
and shuffled.
List<ListPattern> createData () {
var patterns = new ArrayList<ListPattern> ();
for (String validString : validStrings) {
patterns.add (Pattern.makeVerbalList (validString.split("")));
}
Collections.shuffle (patterns);
return patterns;
}
private final String[] validStrings = "TTS,VXS,TPTS,VXXS,VXPS,TPPTS,TTVXS,VXXXS,VXXPS,TPPPTS,TPTVXS,TTVXXS,TTVXPS,VXXXXS,VXXXPS,VXPVXS,TPPPPTS,TPPTVXS,TPTVXXS,TPTVXPS,TTVXXXS,TTVXXPS,VXXXXXS,VXXXXPS,VXXPVXS,VXPVXXS,VXPVXPS,TPPPPPTS,TPPPTVXS,TPPTVXXS,TPPTVXPS,TPTVXXXS,TPTVXXPS,TTVXXXXS,TTVXXXPS,TTVXPVXS,VXXXXXXS,VXXXXXPS,VXXXPVXS,VXXPVXXS,VXXPVXPS,VXPVXXXS,VXPVXXPS".split (",");4.3.2. Ruby
We now explore an implementation of the same model in Ruby.
The following section sets up the experimental data.
# ValidStrings generated from Reber grammar
ValidStrings = <<END
TTS
VXS
TPTS
VXXS
VXPS
TPPTS
TTVXS
VXXXS
VXXPS
TPPPTS
TPTVXS
TTVXXS
TTVXPS
VXXXXS
VXXXPS
VXPVXS
TPPPPTS
TPPTVXS
TPTVXXS
TPTVXPS
TTVXXXS
TTVXXPS
VXXXXXS
VXXXXPS
VXXPVXS
VXPVXXS
VXPVXPS
TPPPPPTS
TPPPTVXS
TPPTVXXS
TPPTVXPS
TPTVXXXS
TPTVXXPS
TTVXXXXS
TTVXXXPS
TTVXPVXS
VXXXXXXS
VXXXXXPS
VXXXPVXS
VXXPVXXS
VXXPVXPS
VXPVXXXS
VXPVXXPS
END
def create_data()
patterns = ValidStrings.split("\n").collect do |str|
JChrest.make_verbal_pattern_from_string(str)
end
patterns.shuffle!
return [patterns[0...18], patterns[21..-1]]
end
def random_string(n)
letters = ["T", "X", "P", "V"]
word = ""
while word.size < n-1
word << letters.sample
end
result = word + "S" # end with 'S'
if ValidStrings.split("\n").include?(result)
return random_string(n)
else
return result
end
end
# create 22 random samples from characters in string
def rndTests()
result = []
7.times do
[6,7,8].each do |size|
result << JChrest.make_verbal_pattern_from_string(random_string(size))
end
end
result << JChrest.make_verbal_pattern_from_string(random_string(7))
return result
endThe list of valid strings is converted into ListPattern objects and then
put randomly into a train / test split. |
|
This function converts the Ruby string into a ListPattern object,
as used by the CHREST interface. |
|
| This function creates a random string, obeying some restrictions on the form of string to create negative examples of the grammar. | |
| A selection of random strings are created, of the required sizes. |
The following functions model the experiment using the CHREST architecture.
In Ruby, it is possible to "reopen a class", and so add methods to the Chrest class
itself. This is a matter of taste, but is illustrated for the first function below.
The following functions retrieves a list of chunks for a given pattern. It does this by first looking up the pattern in the model, removing the part of the pattern that was used in sorting, and then repeating for the remaining part of the pattern. This models a process of scanning a series of symbols, and picking out the chunks in sequence.
class Chrest
def retrieve_chunks(pat)
chunks = []
node = recognise(pat)
chunks << node.contents
new_pat = pat.remove(node.contents)
while not(new_pat.equals(pat))
pat = new_pat
node = recognise(pat)
chunks << node.contents
new_pat = pat.remove(node.contents)
end
return chunks
end
endThe following function builds a CHREST model from a list of patterns. The training process uses a similar decomposition of the pattern into known chunks, as described above, so that it first tries to recognise and learn the whole pattern, before removing the part that was recognised and continuing again with the remainder of the pattern.
# Train model
def train_model(patterns)
model = Chrest.new()
patterns.each do |pat|
model.recognise_and_learn(pat)
node = model.recognise(pat)
new_pat = pat.remove(node.contents)
while not(new_pat.equals(pat))
pat = new_pat
model.recognise_and_learn(pat)
node = model.recognise(pat)
new_pat = pat.remove(node.contents)
end
end
return model
endGiven a trained model and a set of patterns, this method will determine if the model identifies each pattern as an example of the valid set or not. There are two conditions, based on how many chunks are required to recognise each pattern: are there too many small chunks, indicating a lack of knowledge, or are there too many chunks, in which case they cannot all be held in the articulatory loop. If either of the two conditions is not met, then the pattern is classified as invalid.
# Run each test twice
def test_model(model, patterns, valid)
true_res = 0
false_res = 0
2.times do
patterns.each do |pat|
chunks = model.retrieve_chunks pat
# conditions to reject string
# 1. number of small chunks is too large (lack of knowledge)
# 2. number of chunks in total is too large (articulatory loop)
if chunks.inject(0) {|r, chunk| r + (chunk.size <= 1 ? 1 : 0)} > 2 or
chunks.size > 5
if valid
false_res += 1
else
true_res += 1
end
else
if valid
true_res += 1
else
false_res += 1
end
end
end
end
return [true_res, false_res]
endThe following method pulls together the train/test processes, into a single function to run the experiment.
# Test model and report results
def run_expt()
training, testing = create_data()
model = train_model(training)
true_pos, false_neg = test_model(model, testing, true)
true_neg, false_pos = test_model(model, rndTests, false)
return [true_pos, false_neg, true_neg, false_pos]
endThe remainder of the program is relatively straightforward. The experiment is run a number of times, collecting the true/false positive/negative scores, and displaying a summary in the table. The table also shows comparative results, from the source paper.
NumRuns = 100
def format(a, b)
("%5.2f" % (a.to_f / NumRuns)) + "/" + ("%5.2f" % ((a+b).to_f / NumRuns))
end
total_true_pos = 0
total_false_neg = 0
total_true_neg = 0
total_false_pos = 0
NumRuns.times do
true_pos, false_neg, true_neg, false_pos = run_expt()
total_true_pos += true_pos
total_false_neg += false_neg
total_true_neg += true_neg
total_false_pos += false_pos
end
puts
puts "*** Results ***"
puts
puts "Valid Invalid (Actual)"
puts "#{"%5d" % total_true_pos} #{"%5d" % total_false_neg} | Valid (True)"
puts "#{"%5d" % total_false_pos} #{"%5d" % total_true_neg} | Invalid"
puts
puts " Human ACT-R CHREST"
puts "-----------------------------------------------------"
puts " Hits: 33/44 34/44 #{format(total_true_pos, total_false_neg)}"
puts "Correct rejections: 36/44 39/44 #{format(total_true_neg, total_false_pos)}"
puts " Misses: 11/44 10/44 #{format(total_false_neg, total_true_pos)}"
puts " False alarms: 8/44 5/44 #{format(total_false_pos, total_true_neg)}"
puts
puts "(Human/ACT-R from Kennedy & Patterson (2012). "
puts " CHREST results averaged over 100 runs.)"4.4. Example Model : Paired-Associate Learning
CHREST has its roots in the EPAM architecture. EPAM initially specialised in modelling experiments in paired-associate, or verbal, learning, where participants would learn to predict sequences of random words.
Although CHREST shares some similarities with EPAM, in terms of constructing a discrimination net, and its use of the Perceiver for scanning a visual scene, CHREST also has many differences. In particular, CHREST learns complex data relations in a bottom up manner, whereas EPAM learns them in a top down manner. For example, in the verbal-learning experiments, individual patterns must be linked as stimulus-response pairs. In CHREST, this is modelled by learning separate nodes for the stimulus and response patterns and then forming a link between the two. In EPAM, there is a specialised Stimulus-Response-Pair node which is initialised before nodes for the stimulus and response are separately learnt and connected within the larger node.
Because of these differences, CHREST models of verbal learning must be constructed differently to those of EPAM. An example model explores the effect of simulus and response familiarisation: looking at how much quicker learning of a list of words proceeds if either the stimulus or the response words are familiar in advance.
require "jchrest"
# Stimulus-Response pairs
# (taken from EPAM-VI file, Underwood's low-low condition)
Pairs = JChrest.makeSRPairs [
["xin", "vod"],
["toq", "hax"],
["wep", "cem"],
["duf", "jyl"],
["myd", "siq"],
["ruk", "fec"],
["nas", "baj"],
["pov", "loz"],
["kir", "zub"],
["gac", "yug"]
]The following method is used to train the model on each of a list of patterns. This is used to pre-train the model with patterns for the "familiar" conditions.
# train model on given patterns until it recalls them all
# -- timeout is the number of attempts made until it gives up
def train_model(model, patterns, timeout = 100)
cycle = 0
begin
some_unknown = false
cycle += 1
patterns.each do |pattern|
if model.recall_pattern(pattern).nil? or
(model.recall_pattern(pattern) != pattern)
some_unknown = true
model.recognise_and_learn pattern
end
end
end while some_unknown and cycle <= timeout
return cycle # return the number of training cycles required
endThe experiment itself is run by training a model on the pairs, looking to see if it associates each stimulus with the corresponding response. Training continues until the model gets all of the patterns correct.
# train model on given SR pairs until it gets them right
# -- timeout is the number of attempts made until it gives up
# Returns the number of cycles required
def train_model_pairs(model, pairs, timeout = 100)
errors = 0
cycle = 0
begin
some_unknown = false
cycle += 1
pairs.each do |stimulus, response|
if model.associate_pattern(stimulus).nil? or
(model.associate_pattern(stimulus) != response)
some_unknown = true
errors += 1
model.associate_and_learn(stimulus, response)
end
end
end while some_unknown and cycle <= timeout
return cycle
endThe next section trains a model in each of the four conditions, and keeps a record of the number of training cycles needed to learn the sequence. Notice that for the "familiar" cases, the model is first trained with the respective stimuli, responses or both.
def train_u_u_condition
model = Chrest.new
return train_model_pairs(model, Pairs)
end
def train_f_u_condition
model = Chrest.new
train_model(model, Pairs.collect{|p| p[0]})
return train_model_pairs(model, Pairs)
end
def train_u_f_condition
model = Chrest.new
train_model(model, Pairs.collect{|p| p[1]})
return train_model_pairs(model, Pairs)
end
def train_f_f_condition
model = Chrest.new
train_model(model, Pairs.flatten)
return train_model_pairs(model, Pairs)
end
uu = train_u_u_condition
fu = train_f_u_condition
uf = train_u_f_condition
ff = train_f_f_conditionFinally, the results are displayed. Notice that results are given as a ratio of the number of trials taken in the FF condition. For comparison, results for humans, EPAM III and EPAM VI are shown, taken from H. Richman, H.A. Simon, E.A. Feigenbaum, 'Simulations of paired associate learning using EPAM VI', Working paper 553, 2002.
puts "Effects of Stimulus and Response Familiarisation"
puts
puts "Table of Trials to learn list"
puts
puts "Condition People EPAM III EPAM VI CHREST"
puts "--------- ------ -------- ------- ------"
puts " F-F 1.0 1.0 1.0 #{ff.to_f/ff}"
puts " U-F 1.2 1.3 1.9 #{uf.to_f/ff}"
puts " F-U 1.6 1.8 2.8 #{fu.to_f/ff}"
puts " U-U 1.8 2.5 3.7 #{uu.to_f/ff}"
putsThe output shows this CHREST model is performing close to that of EPAM VI. The required result is that prior familiarity of the responses is much more important than prior familiarity with the stimuli.
Effects of Stimulus and Response Familiarisation
Table of Trials to learn list
Condition People EPAM III EPAM VI CHREST
--------- ------ -------- ------- ------
F-F 1.0 1.0 1.0 1.0
U-F 1.2 1.3 1.9 1.5
F-U 1.6 1.8 2.8 2.5
U-U 1.8 2.5 3.7 4.0
4.5. Classification Example
The following script is a simple example of classification using CHREST. The example is the well-known "Weather" example, familiar from data-mining / machine-learning texts. Instances are linked to labels using "naming links", which associate a visual and a verbal pattern: instances are learnt as visual patterns, and the labels as verbal patterns.
require "jchrest"
model = Chrest.new
Weather = [ ["sunny", "hot", "high", "false", "no"],
["sunny", "hot", "high", "true", "no"],
["overcast", "hot", "high", "false", "yes"],
["rainy", "mild", "high", "false", "yes"],
["rainy", "cool", "normal", "false", "yes"],
["rainy", "cool", "normal", "true", "no"],
["overcast", "cool", "normal", "true", "yes"],
["sunny", "mild", "high", "false", "no"],
["sunny", "cool", "normal", "false", "yes"],
["rainy", "mild", "normal", "false", "yes"],
["sunny", "mild", "normal", "true", "yes"],
["overcast", "mild", "high", "true", "yes"],
["overcast", "hot", "normal", "false", "yes"],
["rainy", "mild", "high", "true", "no"] ]
def construct_patterns data
data.collect do |item|
[JChrest.make_string_pattern(["outlook-#{item[0]}",
"temperature-#{item[1]}",
"humidity-#{item[2]}",
"windy-#{item[3]}"]) ,
JChrest.make_name_pattern(item[4])]
end
end
patterns = construct_patterns Weather
12.times do |i|
for pair in patterns
model.learn_and_name_patterns(pair[0], pair[1])
end
print "Performance on cycle #{i} is: "
sum = 0
for pair in patterns
unless model.name_pattern(pair[0]).nil?
sum += 1 if model.name_pattern(pair[0]) == pair[1]
end
end
puts "#{sum} / #{patterns.length}"
end| The "learn_and_name_patterns" method is called to learn and link the two given patterns. | |
| The "name_pattern" method returns the name for the given pattern, if it has been learnt. | |
| Notice that "==" can be used in Ruby to check for pattern equality, and it calls the Java "equals" method in the respective pattern class. |
The model can be displayed by calling:
view = ChrestView.new(nil, model)
The numbers in green indicate the naming link, from the visual nodes describing instances to the verbal node holding the class label.